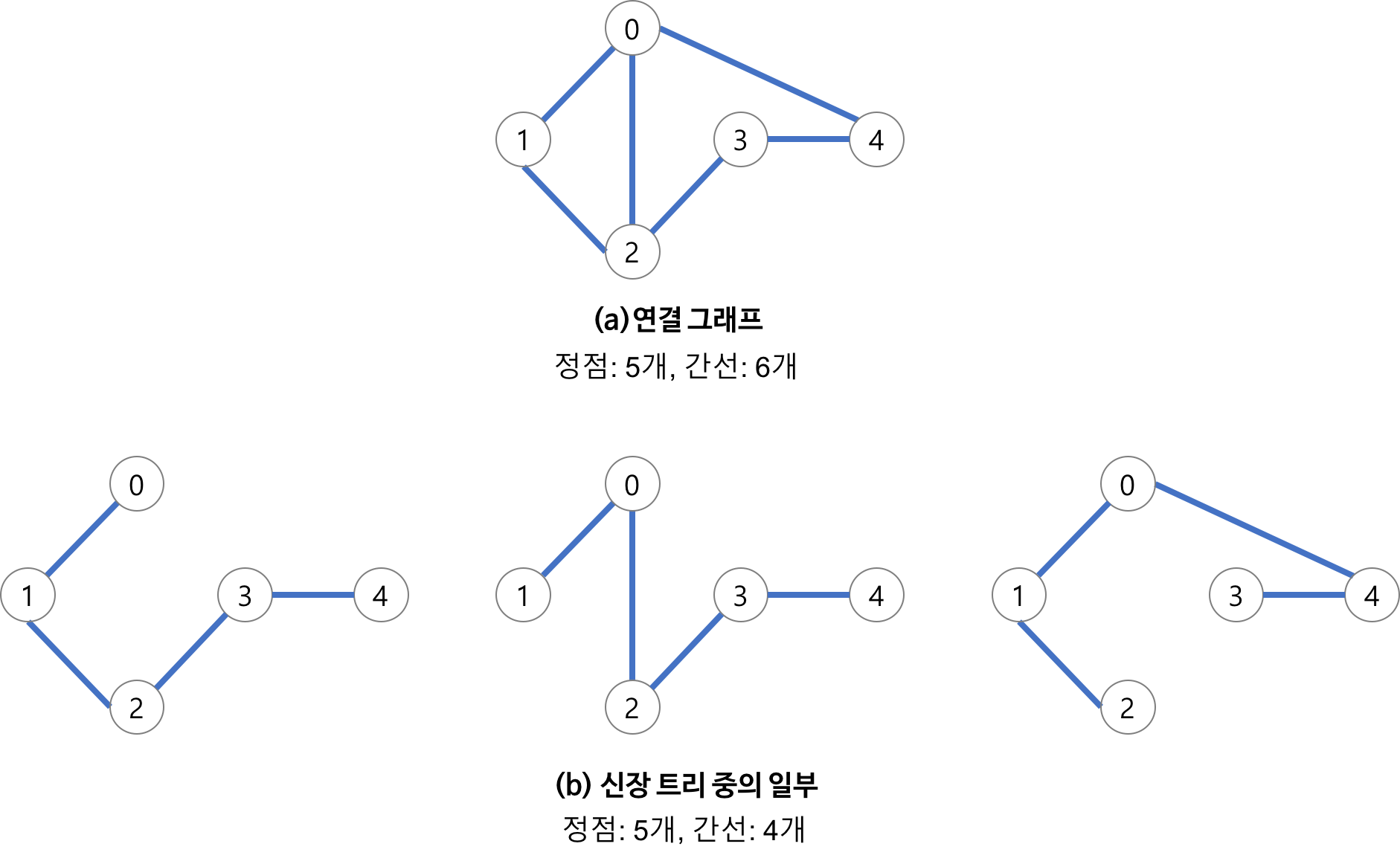
신장 트리(Spanning Tree)
그래프 내의 모든 정점을 포함하는 트리를 말한다.
최소 연결 부분 그래프이다.
신장 트리 특징
DFS, BFS 에 이용된 간선을 모으면 그게 바로 신장트리가 된다.
하나의 그래프의 여러개의 신장 트리 존재
모든 정점이 연결 되어 있어야 하고 사이클을 포함해서는 안된다 .n개의 정점을 n-1개의 간선으로 연결해야 한다.
MST(Minimum Spaning Tree)
간선들의 가중치 합이 최소인 신장 트리
MST를 이용해서 통신망 같은 선로 구축에 최소 비용을 계산할 수 있다.
Kruskal MST 알고리즘
가장 가중치가 낮으면서 사이클을 발생시키지 않는 간선을 선택해나가는 알고리즘
그리디 알고리즘으로 분류
n-1개의 간선이 선택될 때까지 반복
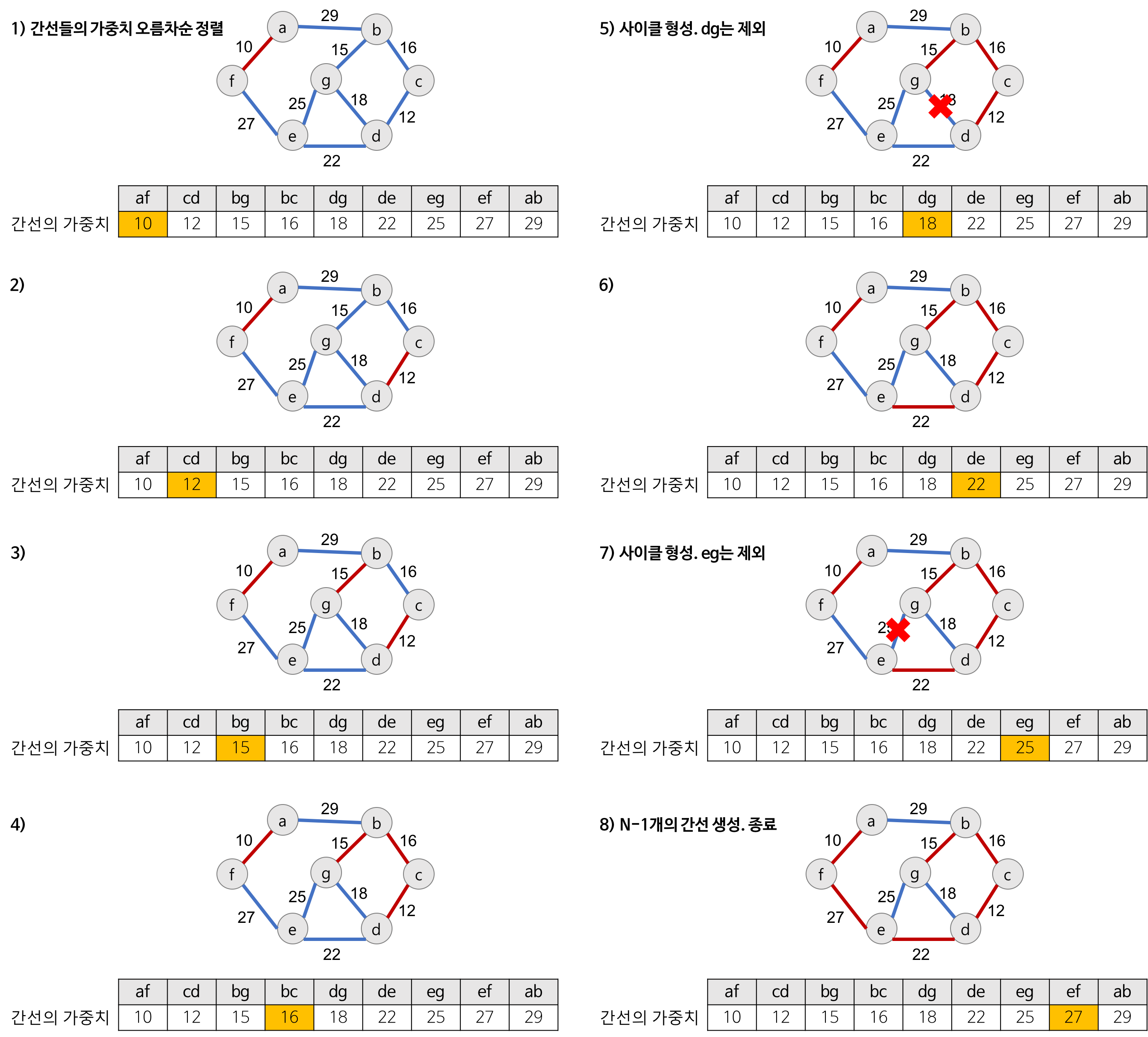
Kruskal 알고리즘 과정
그래프의 간선들을 가중치의 오름차순으로 정렬한다.
가중치가 가장 낮은 간선을 선택한다.
선택한 간선이 사이클을 생성하는지 검사한다.
find 사용해서 parent 노드가 같은지 확인
사이클을 생성하지 않으면 선택한 간선을 현재의 MST에 추가한다.
mst에 추가하고, union 처리해서 같은 그룹으로 묶기
n-1개의 간선이 선택될 때까지 2~4번을 반복한다.
구현
n = 7
edges = [
(4, 7, 18),
(4, 5, 22),
(5, 7, 25),
(5, 6, 27),
(1, 22, 29),
(1, 6, 10),
(3, 4, 12),
(2, 7, 15),
(2, 3, 16),
]
mst = []
parent = [i for i in range(n + 1)]
# 간선 가중치의 오름차순으로 정렬
edges.sort(key=lambda x: x[2])
def find(x):
if x == parent[x]:
return x
return find(parent[x])
def union(x, y):
parent[find(y)] = parent[find(x)]
def kruskal():
for edge in edges:
# n-1개의 간선을 선택하면 종료
if len(mst) == n - 1:
return
# 같은 그룹인지 확인
if find(edge[0]) == find(edge[1]):
continue
# 같은 그룹에 속하지 않으면 mst에 추가 + union
union(edge[0], edge[1])
mst.append(edge)
mst()
시간 복잡도
간선의 갯수가 E, 점정의 갯수가 V 일 때
가선의 가중치를 오름차순 정렬 : O ( E l o g E )
O ( l o g V ) O ( E l o g V )
전체적인 시간복잡도
You can't use 'macro parameter character #' in math mode O(ElogE + ElogV)$$E가 V보다 큰 일반적인 경우 $O(ElogE)$ 로 근사될 수 있다. ## Prim 알고리즘 > 시작 정점에서부터 출발하여 신장트리를 단계적으로 확장해나가는 방법이다. 신장 트리는 결국에 **시작 노드와 마지막 노드는 하나의 간선**을, **그 외의 노드들은 2개의 간선을 선택**하게 된다. 이 특징을 이용해서 시작 정점을 잡고 인접한 정점 중에서 가장 가중치가 낮은 간선을 선택하면서 mst를 형성하는 알고리즘이 prim 알고리즘 이다. ### Prim 알고리즘 과정 1. mst 집합에 시작 정점 추가 2. mst 집합에 인접한 정점들 중에서 가중치 가장 낮은 간선 선택해서 트리 확장 단, mst에 속하지 않는 정점이여야 함 3. n-1개의 간선을 선택할 때 까지 반복 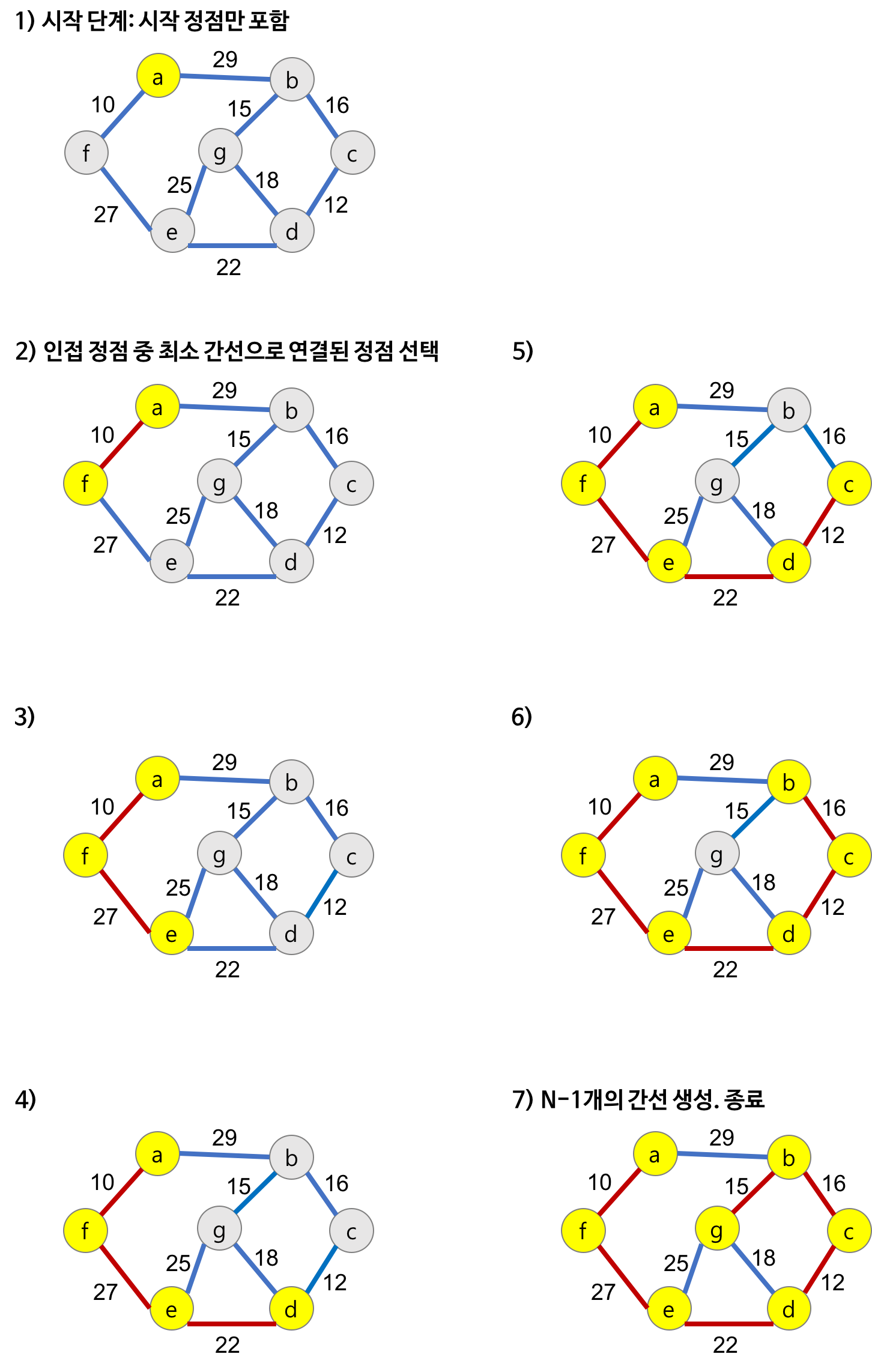 ### 구현 보통 min-heap을 사용해서 구현한다. 1. 첫번째 노드 삽입 후 heap push 2. 가장 가중치 작은 간선 선택, if visited면 continue 3. 방문하지 않았고 가중치 최소인 가중치 mst 추가, 노드 인접 간선 heap push ```python def prim(start): total = 0 heap = [] visited = [False] * (v + 1) heapq.heappush(heap, start) while heap: w, next = heapq.heappop(heap) if visited[next]: continue visited[next] = True total += w for b, c in graph[next]: if visited[b] == False: heapq.heappush(heap, (c, b)) return total ``` ### 시간 복잡도 프림 알고리즘은 우선순위 큐를 사용하는 부분에 의해 결정된다. 간선의 갯수가 E, 정점의 갯수가 V 일 때 - 모든 노드를 탐색하며 heap 삭제 : $O(VlogV)$ - 인접 간선을 찾고 힙에 삽입하는 과정 : $O(ElogV)$ 전체 시간복잡도 $$O(VlogV + ElogV) O(ElogE + ElogV)$$E가 V보다 큰 일반적인 경우 $O(ElogE)$ 로 근사될 수 있다. ## Prim 알고리즘 > 시작 정점에서부터 출발하여 신장트리를 단계적으로 확장해나가는 방법이다. 신장 트리는 결국에 **시작 노드와 마지막 노드는 하나의 간선**을, **그 외의 노드들은 2개의 간선을 선택**하게 된다. 이 특징을 이용해서 시작 정점을 잡고 인접한 정점 중에서 가장 가중치가 낮은 간선을 선택하면서 mst를 형성하는 알고리즘이 prim 알고리즘 이다. ### Prim 알고리즘 과정 1. mst 집합에 시작 정점 추가 2. mst 집합에 인접한 정점들 중에서 가중치 가장 낮은 간선 선택해서 트리 확장 단, mst에 속하지 않는 정점이여야 함 3. n-1개의 간선을 선택할 때 까지 반복  ### 구현 보통 min-heap을 사용해서 구현한다. 1. 첫번째 노드 삽입 후 heap push 2. 가장 가중치 작은 간선 선택, if visited면 continue 3. 방문하지 않았고 가중치 최소인 가중치 mst 추가, 노드 인접 간선 heap push ```python def prim(start): total = 0 heap = [] visited = [False] * (v + 1) heapq.heappush(heap, start) while heap: w, next = heapq.heappop(heap) if visited[next]: continue visited[next] = True total += w for b, c in graph[next]: if visited[b] == False: heapq.heappush(heap, (c, b)) return total ``` ### 시간 복잡도 프림 알고리즘은 우선순위 큐를 사용하는 부분에 의해 결정된다. 간선의 갯수가 E, 정점의 갯수가 V 일 때 - 모든 노드를 탐색하며 heap 삭제 : $O(VlogV)$ - 인접 간선을 찾고 힙에 삽입하는 과정 : $O(ElogV)$ 전체 시간복잡도 $$O(VlogV + ElogV) E가 V보다 큰 일반적인 경우 O ( E l o g V )
정확히자면 힙에는 노드가 아니라 간선이 삽입된다.O ( l o g E ) O ( l o g X ) ( V <= X <= E )
Kruskal vs Prim
간선의 갯수 E,정점의 갯수 V 일 때O ( E l o g E ) O ( E l o g V )
따라서 간선의 갯수가 많은 밀집그래프의 경우 크루스칼 알고리즘이 유리하고, 간선의 갯수가 적은 희소 그래프의 경우 프림 알고리즘이 유리하다.
references